TLP基本格式
事务(Transactions)由请求(Requests)和完成(Completions)组成, 它们使用传输层包(Transaction Layer Packets,简称TLP)通信。PCIe 支持几种基本的事务类型:内存(Memory),I/O,配置(Configuration) 和信息(Message)。他们的作用如下:
| 地址空间 | 事务类型 | 描述 |
|---|---|---|
| Memory | Read/write | 将数据传输到内存映射的位置 |
| I/O | Read/write | 将数据传输到I/O映射位置 |
| Configuration | Read/write | 设备功能配置/设置 |
| Message | Baseline | 从事件信号机制到通用消息 |
TLP由TLP Prefixes + TLP Header + Data Payload + TLP Digest构成 ,如下图所示:

当 TLP 形成时, 所有为保留(Reserved,R)的字段必须用 0 填充, 接收机在接受 TLP 时必须忽略这些保留的字段, 并且 Switches 在转发时也不能修改。
PCIe采用小端模式,传输时先传输 TLP Prefixes, 最后传输 TLP Digest, TLP Prefixes为TLP的前缀,可以没有,也可以有多个,TLP Header针对串行互连的性能进行了优化,最重要的信息首先传递. 在 TLP 标头, 地址会先传输,对端可以先对地址进行解析。Data Payload为数据载荷,根据TLP类型的不同,可以没有,也可以有,长度不定,TLP Digest为TLP后缀,可以没有,也可以有一个。
Flit模式下,TLP可能包含如下的字段:
- 0个或者超过1个DW的Local TLP prefixes
- TLP Header Base是由Type[7:0]字段,接着跟0到7个DW的OHC(Orthogonal Header Content,正交头内容)来表征,OHC个数由OHC[4:0]字段决定
- TLP data payload是0到1024DW
- 如果存在TLP Trailer,是有TS[2:0]域来指示
TLP Prefixes
Non Flit模式下所有的TLP prefixes 和Header都包含Fmt和Type字段。

在Non Flit模式下,对任意 TLP, 如果 TLP 的byte 0的Fmt字段为100b, 那么该 TLP 中存在 TLP Prefixes, 并且 TLP Header 中的 Type[4] 用于确定该 TLP Prefixes 的类型。
- Type[4] : 0, 表明是一个 Local TLP Prefixes
- Type[4] : 1, 表明是一个 End-End TLP Prefixes
Flit Mode下所有的TLP Prefix第一个DW都具有如下字段
不仅是TLP Prefix,Flit模式下的所有TLP的第一个DW都具有上述的所有字段。在Flit模式下,Type[7:0]如果为为下列值时,表明存在Prefix
- 1000_xxxx 1000_10xx 1000_1100 1000_1101 1000_1110 1000_1111
TLP Prefixes的大小是一个DW(4 Byes),但是一个TLP中可以有多个TLP Prefixes。
TLP Prefixes 规则
TLP Prefixes Byte 1到3的具体内容取决于Fmt和type字段。如果TLP中有Prefixes,则该TLP中必须有Header,不能只传输Prefixes。如果接收只有Prefixes的TLP,则该TLP是一个Malformed TLP(无效的TLP),Malformed TLP必须上报错误,并且跟端口关联上。
TLP Prefixes可以有一个或者多个,并且类型也可以不一样,即一个TLP中可以同时包含Local TLP Prefixes和End-End TLP Prefixes,但是所有的Local TLP Prefixes必须要在End-End TLP Prefixes之前,如果收到的TLP中,End-End TLP Prefixes在Local TLP Prefixes之前,则是一个无效的TLP
Local Prefixes和End-End TLP Prefixes有不同的处理规则。
Local Prefixes处理规则
Prefixes有不同的类型,同样Local Prefixes也有不同的类型,其类型取决于Type字段的[3:0],根据Type[3:0]的不同可分为下面几种类型
| Local TLP Prefix类型 | Type[3:0] | 描述 |
|---|---|---|
| MR-IOV | 0000 | MR-IOV TLP Prefix |
| FlitModePrefix | 1101 | Flit Mode Local TLP Prefx |
| VendPrefixL0 | 1110 | Vendor Defined Local TLP Prefix |
| VendPrefixL1 | 1111 | Vendor Defined Local TLP Prefix |
| xxx | xxx | 其它编码保留 |
VendPrefixL0和VendPrefixL1都属于Vendor Defined Local TLP Prefix。
不同类型的Local TLP Prefix具有不同的大小,路由规则和流控规则。
如果接收机收到不支持某种类型的Local TLP Prefix,对接收机而言是一种错误(协议没有针对说明是rc还是ep还是switch)。如果此时Extended Fmt Field Supported域为1,收到不支持类型的Local TLP Prefix为无效的TLP,除非在其它协议中(如设计明确规定)明确声称这种TLP不是无效的TLP。如果此时Extended Fmt Field Supported域为0,收到不支持的Local TLP Prefix时,其行为却决于设备自己实现。
Local TLP Prefix不受ECRC保护
Vendor Defined Local TLP Prefix
为了操作性和灵活性最大化,Vendor Defined Local TLP Prefix的规则也有一定的变化。
如果没有使用vendor-specific机制,component之间是不允许发送包含Vendor Defined Local TLP Prefix的TLP。使用vendor-specific机制机制后,只要同时满足Extended Fmt Field Supported域为1和支持Fmt中的所有定义时,才可以使用Vendor Defined Local TLP Prefix。
为了所有的vendor defined prefixes都可以使用Vendor Defined Local TLP Prefix编码中的任意一种,协议推荐Components可以通过vendor-specific去配置。
FLit Mode Local TLP Prefix
这种Prefix只允许出现在Flit模式中。其格式如下所示:
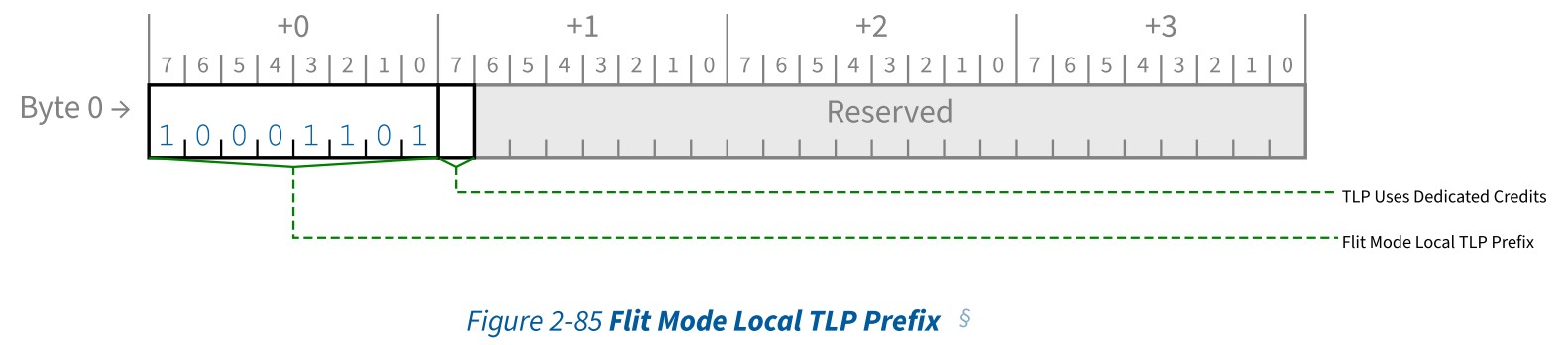
Flit Mode Local TLP Prefix包括TLP Uses Dedicated Credits,当改比特为1时,表明TLP必须使用dedicated flow control credits(专用流控信用)来处理相关联的TLP。当此比特为0时,或者是不存在Flit Mode Local TLP Prefix时,相关联的TLP必须使用shared flow control credits(共享流控信用)来处理
如果Flit Mode Local TLP Prefix(Byte 1的bit[7])用在了Non Flit Mode TLP中,这在Flit模式下是一个错误,并且必须视为无效的TLP。允许将Flit Mode Local TLP Prefix用在任何Flit模式下的TLp中,但是强烈推荐只有需要Prefix存在时,才使用Flit Mode Local TLP Prefix.
End-End TLP Prefix处理 – NFM
注意: 该部分只适用于Non-Flit Mode,FLIT模式下的End-End TLP Prefix用OHC-E代替了,所以FLIT模式下不支持End-End TLP Prefix
如果该Prefix是End-End TLP Prefix,则Type[4]必须为1b,Type[3:0]决定了End-End TLP Prefix的类型。
| End-End TLP Prefix类型 | E[3;0] | 描述 |
|---|---|---|
| TPH | 0000 | TPH |
| PASID | 0001 | PASID |
| IDE | 0010 | 定义一个IDE TLP |
| VendPrefixE0 | 1110 | Vendor Defined End-End TLP Prefix |
| VendPrefixE1 | 1111 | Vendor Defined End-End TLP Prefix |
| x | x | 其它编码保留 |
Device Capabilities 2寄存器的Max End-End TLP Prefixes字段表明了function支持End-End TLP Prefixes数量。TLP中End-End TLP Prefixes的最大数量为4,如果接收机接收到的TLP中,End-End Prefixes大于4,那么该TLP是一个Malformed TLP(rc,ep,switch都有效)。
Max End-End TLP Prefix在不同的设备需求不同:
- 在RC中,Max End-End TLP Prefixes的值允许小于硬件实际支持的。
- 除RC外,其它设备(如EP)收到的TLP中,End-End TLP Prefixes如果超出了设备支持的上限,则该TLP必须视为一个Malformed TLP。如果支持AER(Advanced Error Reporting),发生该错误后,必须记录在AER中。
如果RC中Max End-End TLP Prefixes字段小于硬件实际支持的,错误处理必须基于Max End-End TLP Prefixes域中的值。如果RC收到的TLP中End-End TLP Prefixes超过所支持的,必须做如下的处理:
- 推荐把Requests(如EP发的MWR)处理为UR(Unsupported Requests,不支持的请求),如果不处理为UR,则必须处理为Malformed TLPS。
- 推荐把Completions处理为UR,如果不处理为UR,则必须处理Malformed TLP。
- 如果在Ingress Port收到了带End-End的TLP,这是一个跟Ingress Port相关联的错误。
- 如果从Egress Port发出了带End-End的TLP,这个跟Egress Port相关联的错误
如果接收机不支持End-End TLP Prefixes,收到带有End-End TLP Prefix的TLP是一个错误,接受需要把这个TLP处理为Malformed TLP,并且需要跟接受端口绑定。
对于软件的要求:如果component不支持End-End TLP Prefixes,软件必须确保不能发送带End-End TLP Prefixes的TLP。如果组件的Extend Fmt Field Supported比特被清了,可能会导致误认为TLPs中包含TLP Prefixes。
如果Upstream Port的其中一个function(function只有rc或者ep才有,switch为bridge)的End-End TLP Prefix Supported比特设置了,Upstream Port的所有function都必须能处理带不支持的End-End TLP Prefix类型的TLP,处理结果为UR,并且需要个端口绑定。如果收到的是Completion,且该Completion中带有不支持的End-End TLP Prefix类型,Upstream Port的所有function都需要有能力把该笔Completion处理为UC(Unexpected Completion,不支持的回复),并且需要跟端口绑定。
对于switch的要求如下:
- 如果End-End TLP Prefix Supported比特为1,Switch必须要能够转发包含4个End-End TLP Prefixes的TLP,如果TLP是受到ECRC保护的,那么End-End TLP Prefixes也是受到ECRC保护的。
- 对于路由的元素,在每个Egress Port(出口)的End-End TLP Prefix Blocking比特决定了改TLP通过Egress Port发出去时是否包含了End-End TLP Prefixes。
- 如果转发被阻断,整个TLP都将会被丢弃,并且需要报告未TLP Prefix Blocked Error。
- 如果被阻挡得TLP是一个Non-Posted请求(如MRd),Egress Port需要返回一个Completion且Completion中得Status未Unsupported Request(UR)。TLP Prefix Blocked Error上报时需要跟Egress Port绑定
对于启用多播的路由元素,End-End TLP Prefixes在所有多播的TLP中都需要加上,在每一个Egress Port上,多播包中的TLP Prefix Egress Blocking是相互独立的。
PASID Prefix
在非Flit模式下,PASID TLP Prefix是一个End-End TLP Prefix。在Flit模式下,当存在PASID时,它被包含在OHC-A1和OHC-A4中,非Flit模式下PASID Prefix如下图所示
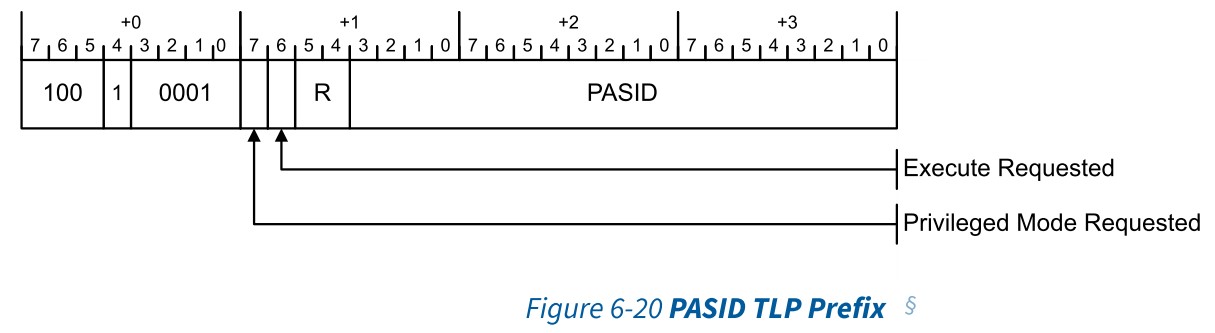
| bits | 描述 |
|---|---|
| Byte 0 bit[7:5] | 100b – 表明是一个TLP Prefix |
| Byte 0 bit[4] | 1b – 表明是一个End-End TLP Prefix |
| Byte 0 bit[3:0] | 0001b – 表明是一个PASID TLP Prefix |
| Byte 1 bit[7] | Privileged Mode Request – 如果Set表示端点中的特权模式实体正在发出请求,如果Clear表示端点中的非特权模式实体正在发出请求。 |
| Byte 1 bit[6] | 如果设置表示端点正在请求执行权限。如果清除,表示端点没有请求执行权限。 |
| Byte 1 bit[3:0] – Byte 3 bit[0] | Process Address Space ID(PASID) – 表明改TLP中相关联得PASID的值 |
Execute Requested
如果Execute Requested比特设置了,EP正在请求允许EP执行与此请求相关联的内存范围内的指令, 具体执行权限协议没有说明。只要Execute Permission Supported比特和Execute Permission Enable都设置后,EP才允许发送带Execute Requested比特为1的TLP
对于RC而言,是否支持Execute Requested是可选的,RC是否支持Execute Requested取决于具体实现,协议强制建议RC不支持Execute Requested。默认RC不支持该机制,如果RC支持,则根据具体实现使能Execute Requested比特。
Privileged Mode Requested
当PASID存在时,PASID的值跟Requester ID的值一起定义了该笔请求需要处理的地址空间ID。PASID只能存在于几种特定类型的TLP中:
- 该表请求包含Address Type(AT)字段,类型为Untranslated(编码为00b)或者Translated(编码为10b).
- NOTE:Configuration请求虽然AT[1:0]也是00b,但是AT[1:0]在Configuration中是没有编码的,所以Configuration不能带PASID
- Flit模式下的地址翻译请求(Address Translation Requests,比如MRd中AT为10b),ATS无效请求消息,页请求消息(Page Request Messages),地址路由消息(Address routed mesages)
- PRT响应消息(PRG Response Messages)
除上述类型的TLP外,其它所有的类型的TLP都不能携带PASID
Vendor Defined End-End TLP Prefix
Vendor Defiend End-End TLP Prefix包括VendPrefixE0和VendPrefixE1,为了最大限度地提高互操作性和灵活性,Vendor Defiend End-End TLP Prefix有以下规则:
- 组件不允许发送包含Vendor Defiend End-End TLP Prefix的TLP,除非是明确指示可用(通过vendor-specific机制)
- 使用vendor-specific机制时,对于两种编码的Vendor Defined End-End TLP Prefix,可用使用那些建议是可配置。这样做允许在单个PCI Express拓扑中同时使用两个不同的Vendor Defined End-End TLP Prefixes,而不要求每个源都了解其发送的每个TLP的最终目的地。
Root Ports with End-End TLP Prefix Supported
在Root Ports之间,能否点对点的传输包含End-End TLP Prefixes的TLPs,这一特征是可选的,并且是实现是相互独立的。如果在两个或者更多RC之间,RC支持End-End TLP Prefix路由能力,则必须在每个RC的Device Capabilities 2寄存器中的End-End TLP Prefix Supported中体现出来.
在所有设置了End-End TLP Prefix Supported的RC对,RC也不要求支持必须支持End-End TLP Prefix路由,如果在不支持的RC对,路由了带有End-End TLP Prefixes的TLP Request,RC必须把它UR; 如果是路由了带End-End TLP Prefixes的Completion,RC必须把它处理Unexpected Completion(UC)。在这两种情况下,错误都是由发送端口报告
对于支持转发由主机软件或RCiEPs(Root Complex Integrated Endpoints)发起的带有End-End TLP Prefix的TLP,必须设置End-End TLP TLP Prefix Supported比特位1。对于支持将Ingress Port(端接收到的带有End-End TLP前缀的TLP转发到RCiEPs的RC,必须设置End-End TLP Prefix SUpported比特。
如果RC都支持带End-End TLP Prefix的TLP,不同的RC允许Max End-End TLP Prefixes有不同的值。
当RC在根端口之间进行对等路由时,如果将一个TLP拆分为多个小TLP,则必须在每个小TLP中复制原TLP的End-End TLP前缀
TLP Header
Non Flit TLP Header
在non-flit模式下,所有的TLP的header都具有如下字段(第一个DW),根据TLP类型的不同,TLP Header可能还会包含其它额外的内容(第二个到第4个DW,下图中没显示)。byte 1的bit[1]为LN,但是已经弃用,所以为R

第一个DW中的各个字段含义如下:
| 比特 | 域 | 含义 |
|---|---|---|
| byte 0 bit[7:5] | Fmt[2:0] | TLP格式,是否有 TLP Prefixes 这些 |
| byte 0 bit[4:0] | Type[4:0] | 与Fmt[2:0]共同决定TLP类型 |
| byte 1 bit[7] | T9 | Tag[9] |
| byte 1 bit[6:4] | TC | traffic class,用于流量控制 |
| byte 1 bit[3] | T8 | Tag[8] |
| byte 1 bit[2] | A2 | Attr[2],ID-Based Ordering(IDO),基于ID的Ordering |
| byte 1 bit[1] | R | 保留位,以前用作轻量化通知(Lightweight Notification,简称LN) |
| byte 1 bit[0] | TLP Hints | 简称TH, 为1表示TLP Header中存在TLP Processing Hints和可选的TPH Prefix |
| byte 2 bit[7] | TD | 为1表示在TLP末尾存在TLP Digest(ECRC),大小为1个DW, 32比特 |
| byte 2 bit[6] | EP | 为1表示TLP是poisoned的 |
| byte 2 bit[5:4] | Attr[1:0] | Attr[1] : Relaxed Ordering Attr[0] : No Snoop |
| byte 2 bit[3:2] | AT | Address Translation,地址转换相关 |
| byte 2 bit[1:0] + byte 3 bit[7:0] | Legnth[9:0] | TLP中data payload的长度 |
== 第1个DW中可能有 ==
Fmt字段
TLP的格式, byte 0 的 bit[7:5],pcie中1个DW为4 bytes,也就是32比特。
| Fmt[2:0] | 描述 |
|---|---|
| 000b | 3 DW header, 没有数据 (无 Data Payload 字段) |
| 001b | 4 DW header, 没有数据 |
| 010b | 3 DW header, 有数据 (有 Data Payload 字段) |
| 011b | 4 DW header, 有数据 |
| 100b | TLP 前缀 |
| others | 其余剩下的编码保留 |
Type[4:0]字段
TLP的类型, byte 0 的bit[4:0], 与 Fmt[2:0] 一起决定 TLP 的类型. Fmt 字段表示存在一个或多个TLP前缀,Type字段表示关联的 TLP 前缀类型, TLP报头的Fmt和Type字段提供了确定TLP报头剩余部分的大小所需的信息,以及包是否在报头后面包含数据负载。
| TLP 类型 | Fmt[2:0] | Type[4:0] | 描述 |
|---|---|---|---|
| MRd | 000/001 | 00000 | 内存读请求 |
| MRdLK | 000/001 | 00001 | 内存读请求锁住 |
| MWr | 010/011 | 00000 | 内存写请求 |
| IORd | 000 | 00010 | I/O 读请求 |
| IOWr | 010 | 00010 | I/O 写请求 |
| CfgRd0 | 000 | 00100 | 配置读类型 0 |
| CfgWr0 | 010 | 00100 | 配置写类型 0 |
| CfgRd1 | 000 | 00101 | 配置读类型 1 |
| CfgWr1 | 010 | 00101 | 配置写类型 1 |
| TCfgRd | 000 | 11011 | 弃用的 TLP 类型 |
| TCfgWr | 010 | 11011 | 弃用的 TLP 类型 |
| Msg | 001 | 10r2r1r0 | 消息请求, r[2:0] 指定消息路由机制 |
| MsgD | 011 | 10r2r1r0 | 有数据载荷的消息请求, r[2:0] 指定消息路由机制 |
| Cpl | 000 | 01010 | 没有数据的完成报文, 用于具有完成状态的 I/0 和 配置写. 除了成功完成以外,还用于原子操作完成和读取完成状态(I/O,配置或内存). |
| CplD | 010 | 01010 | 有数据的完成报文, 用于内存, I/O 和 配置读完成, 也可用于原子操作完成 |
| CplLk | 000 | 01011 | 没有数据的锁定内存读完成, 只在错误情况下使用 |
| CplDlk | 010 | 01011 | 锁定内存读完成, 否则像 CplD 一样 |
| FetchAdd | 010/011 | 01100 | 提取并添加Atomicop请求 |
| Swap | 010/011 | 01101 | Unconditional Swap AtomicOp 请求 |
| CAS | 010/011 | 01110 | 比较和交换原子操作 |
| LPrfx | 100 | 0L3L2L1L0 | 本地 TLP 前缀, L[3:0] 指定本地TLP前缀类型 |
| EPrfx | 100 | 1E3E2E1E0 | 末端 TLP 前缀, E[3:0] 指定末端 TLP 前缀类型 |
| 其它编码保留 |
T9字段
如果支持10bit tag,该字段为Tag[9]
TC[2:0]字段
| TC 域的值(b) | 描述 |
|---|---|
| 000 | TC0:通用IO,GPIO, 默认 TC, 每个 PCIe 设备都必须支持 |
| 001 到 111 | TC1 到 TC7, 差异化服务类, 基于加权轮询(WRR : Weighted-Round-Robin)和/或优先级的区分 |
T8字段
如果支持10bit tag,该字段为Tag[8]
A2字段
Attr[2]
LN字段
byte 1 的 bit[1], Lightweight Notification, 轻量级通知,1 表示内存请求是一个 LN 读或者写, 或者完成是 LN 完成。但是已经弃用了LN协议,所以改比特在非Flit模式为保留位。在Flit Mode下不支持改LN。
TH字段
byte 1 的 bit[0], TLP Hints, 1 表示在 TLP header 中存在 TLP 处理提示(TPH : TLP Processing Hints) 和 TPH TLP Prefix (如果存在)
Attr字段
Attr[1:0]为byte 2的bit[5:4],Attr[2]为byte 1的bit[2]
| Attr比特 | 作用 |
|---|---|
| Attr[2] | ID-Based Ordering,基于ID的序 |
| Attr[1] | Relaxed Ordering,轻松的序 |
| Attr[0] | No Snoop,没有硬件一致性管理 |
该字段是事务标识符,Attributes字段用来提供额外的信心,这些信息允许修改事务的默认处理方式,在系统中,这些修改适用于事务处理的不同方面,比如说:
- Ordering,事务的序
- 硬件一致性管理(snoop)
Attr允许是hint,允许但是不要要求在处理traffic时进行优化,优化支持的级别取决于特定PCI Express外设和平台构建块的目标应用程序。在Flit模式下,Attr在TLP Header中是连续的。在Non Flit模式下,Attr[2]有时被标记为A2,并且不与bit[1]和bit[0]相邻
Attr[2:1]
Attr[2:1]的功能如下所示
| Attr[2] | Attr[1] | Ordering类型 | Ordering模型 |
|---|---|---|---|
| 0 | 0 | 默认Oredring | PCI Strongly Ordered Model, PCI强有序模型 |
| 0 | 1 | Relaxed Ordering,弱序 | PCX-X Relaxed Ordering Model, PCI-X弱序模型 |
| 1 | 0 | ID-Based Ordering (IDO),基于ID的序 | 基于Requester/Completer ID的序,独立的序 |
| 1 | 1 | 弱序+基于ID的序 | Relaxed Ordering 和 IDO 的逻辑或 |
- Relaxed Ordering和ID-Based Ordering Attributes
- Attr[1] 不适用于Configuration,I/O,message Signaled Interrupts(MSI)的memroy和Messageq请求(除非是明确允许),并且Attr[1]必须被清掉
- Attr[2],IDO,在Configuration和I/O请求中是保留的,对所有Memory请求,包括Message Signaled Interrupts(MSI/MSI-X)都不是保留的。IDO对于message请求也不是保留的,除非明确禁止。只有当Requester中,Device Control 2寄存器的IDO Request Enable比特为1时,Requester才允许设置IDO。
- 如果TLP是无效的,接收机禁止考虑IDO的值
- 只有当Device Control 2寄存器的IDO Completion Enable字段为1时,Completer才允许设置IDO。对于一笔请求,不要求复制请求的IDO值到Completion。如果Completer使能了IDO,推荐Completer在所有的completions中都设置IDO,除非是明确的原因不需要设置。
- 在RC之间,如果RC支持转发点对点的TLP,在从Ingress到Egress port时,RC不要求保存IDO的值
Attr[0]
Attr[0]的功能如下
| Attr[0] No Snoop Attribute(b) | Cache一致性管理类型 | 一致性模型 |
|---|---|---|
| 0 | 默认 | 期望硬件强制缓存一致性 |
| 1 | No Snoop | 不期望硬件强制缓存一致性 |
Attr[0] 禁止用于Configuration,I/O,Message Signaled Interrupts(MSI)的memory和Message请求(除非显示表明允许)
TD 字段
- byte 2 的 bit[7], 1 表示 TLP Digest(后缀) 以单个双字(DW)的形式出现在 TLP 的末尾
EP 字段
- byte 2 的 bit[6], Error Poisoned, 1 表示 TLP 无效
AT 字段
Byte 2 的bit[3:2] TA : Translaion Agent,转换代理。AT编码如下
| AT[1:0] | 助记符 | 含义 |
|---|---|---|
| 00b | Untranslated(未翻译) | TA会把地址当成虚拟地址或者物理地址 |
| 01b | Translation Request(翻译请求) | TA会返回一笔read completion,其地址域中的地址为转换后的地址,TA在收到一笔非memory read的memory请求时,如果AT字段为01b,TA会把该笔请求当作UR |
| 10b | 翻译(Transalted) | 在事务中的地址,已经经过ATC翻译。 |
| 11b | 保留(Reserved) | 如果收到内存请求TLP,并且AT域为11b,TA会把该TLP标记成UR(Unsupported Request) |
AT字段只在下列请求中定义:
- Non Flit模式下的内存请求
- Flit模式下基于地址路由的消息请求
在其它所有TLP中都是保留的,即IO和Configuration中即使AT字段的值为00b,也不表示Unstranslated
Length[9:0] 字段
表明TLP中data payload的长度,TLP 的数据必须是 4-byte(1DW) 对齐, 并且只能以 DW的整数为增量
| length[9:0] | 对应的 TLP 数组载荷大小 |
|---|---|
| 00 0000 0001b | 1 DW |
| 00 0000 0010b | 2 DW |
| … | … |
| 11 1111 1111b | 1023 DW |
| 00 0000 0000b | 1024 DW |
== 第2到4个DW可能有 ==
Requester ID[15:0]
Requster ID是Bus Number, Device Number和Function Number的组合,在一个层次结构(hierarchy)中,Function Number是requester(发起者)的独一无二的标识。对于ARI Requester ID,传统上用于Device Number字段的位被用于扩展Function Number字段,并且Device Number实现为0。
Completer ID[15:0]字段
用于指示指示Completer, 在同一个Hierachy下,每一个PCIe Function都有一个独一的Completer ID[15:0],ARI和non-ARI设备Completer ID组成不同
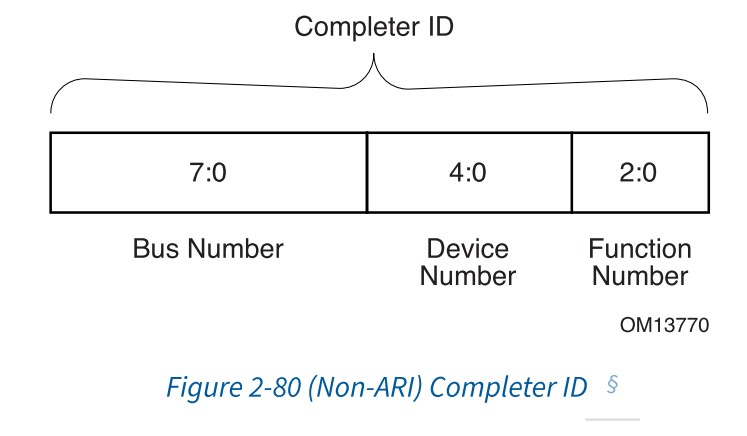
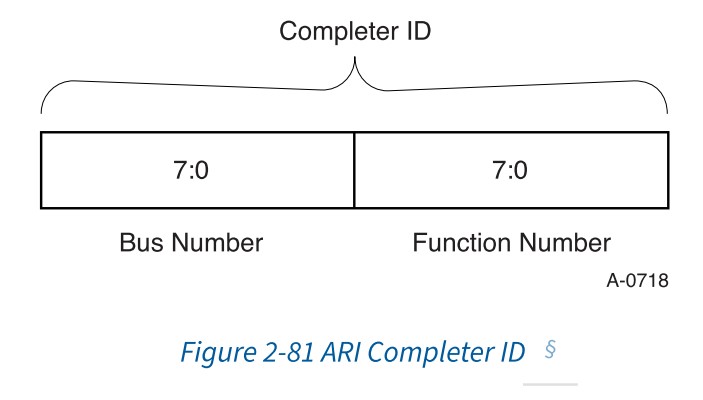
在完成设备的软件初始化和配置(使用至少一个配置写请求)之前,Completer ID字段是没有意义的,对于这种情况,请求者必须忽略Completer ID字段返回的值。
Function如果收到一笔”Type 0 Configuration Write Request Requests”,并且该笔Request需要收到此Function回Compeltion,则该function必须捕获Requets中的Bus Number和Device Number,并且该function产生的Completions中,Bus Number和Device Number必须在的Completer ID中体现出来。
- 如果function必须在初始设备配置写请求之前生成completion,则必须在bus number和device number中填充0
- 在运行时,bus number和dvice number可能会发生变化,因为对于每一笔Configuraton Write Request,都有必要重新捕获bus number和device number
- 也存在一些例外,在RC里面可能以一种自定义实现的方式指定bus number和device number
在某些情况下,具有UR Completion Status的Completion可以由MFD生成,而无需将Completion与设备中的特定功能相关联,在这种情况下,Function Number域是保留的
Completion Status[2:0]
用于指示Completion的状态,cpl.status的编码为
| cpl.status[2:0](二进制编码) | Completion状态 |
|---|---|
| 000 | Successful Completion (SC) |
| 001 | Unsupported Completion (UR) |
| 010 | Request Retry Status (RRS) |
| 100 | Completion Abort (CA) |
BCM – Byte Count Modified
- PCIe Completers禁止使用,只能由PCI-X completers设置
Byte Count[11:0]
- 请求的剩余字节数
- Byte Count的值用1’b1表示1 byte,1111 1111 1111b表示4095 byte,0表示4096 byte
- 针对Memory Read Completions, Byte Count[11:0]具有一定的规则
- 针对AtomicOp Completions, Byte Count值必须跟AtomicOp可操作的字节大小数相关联
- 对于其它类型的Completions,Byte Count的值必须是4
Lower Address[6:0]
- Completion起始的低byte地址
- 对于Memory Read Completions,该字段中的值是Completion返回的第一个启用的数据字节的字节地址
- 对于AtomicOp Completions,Lower Address域是保留的
- 对于其它剩下类型的Completions,此域设置为全0。接收机可以检查是否违反了该项规则(可选的,非强制)
Register Number[5:0]
Extended Register Number[3:0]
First/Last DW Byte
Byte 使能会出现在 Memory, I/O 和 Configuration 请求. 当 Byte Enable 出现在请求的 header 中时,它位于 TLP Header 中的 Byte 7

- First DW BE[3:0]字段表明请求中第一个DW的位置,如果length字段表明请求的长度大于1DW,First DW BE[3:0]禁止为0000b
- Last DW BE[3:0]表明请求中的最后一个DW的位置,如果length字段表明请求的长度大于1个DW,Last DW BE[3:0]禁止为0000b
- 对于Byte Enables字段的每一个比特,如果某个比特为0,则表明数据的第几个byte禁止写入,或者如果是非预取的,completer(完成者)禁止读, 如果某个比特为1,则表明数据的对应的byte是可以写的或者complter是可以读的。
-
比如First DW BE[3:0]是1110b,则表明第一个DW的byte 0是无效的,TLP的开始是从Byte 1开始的
-
- 对于1DW长度的请求,First DW BE允许非连续的Byte Enables(enabled byte被non-enabled byte分开)
-
比如First Byte Enable为1010b,0101b,1001b,1011b,1101b。
-
- 对于长度为2Dw(1Qw)的Quad Word(QW)对齐内存请求,在Byte enable字段中允许非连续字节启用。所有长度为2Dw(1qw)非QW对齐的memory请求和长度大于等于3Dw的memory请求必须只启用与请求的第一个DW和最后一个DW之间的数据连续的字节。
- 连续的Byte Enable例子
-
First DW BE : 1100b, Last DW BE : 0011b
-
First DW BE : 1000b, Last DW BE : 0111b
- 下表列出了Byte Enable与影响的数据Byte
| Byte Enables | 在Header中的位置 | 影响的数据byte |
|---|---|---|
| First DW BE[0] | Byte 7 bit 0 | Byte 0 |
| First DW BE[1] | Byte 7 bit 1 | Byte 1 |
| First DW BE[2] | Byte 7 bit 2 | Byte 2 |
| First DW BE[3] | Byte 7 bit 3 | Byte 3 |
| Last DW BE[0] | Byte 7 bit 4 | Byte N-4 |
| Last DW BE[1] | Byte 7 bit 5 | Byte N-5 |
| Last DW BE[2] | Byte 7 bit 6 | Byte N-6 |
| Last DW BE[3] | Byte 7 bit 7 | Byte N-7 |
- 没有bytes enabled且长度为1DW的写请求是允许的,除非另外指定,不然completer上没有作用
- 设置可以不带Bytes Enabled的1DW写请求或者是“0长度的写”,通常这种行为是用在特定的协议中,用于实现预期的副作用
对于TH比特为1的Memory Read和DMWr请求,Byte Enable字段被用来携带ST[7:0]字段。当可以接受完成这些请求时(就好像所有请求的数据都是使能了一样),Memory Read和DMWr请求中必须设置TH比特
在Memroy Read和DMWr中,如果TH比特设置了,Byte Enable将会有如下的限制
- 如果Length字段表明改请求的长度是1DW,那么First DW Byte Enables的值实现为1111b,且Last DW Byte Enables的值实现为0000b
- 如果Length字段表明该请求的长度大于1DW,那么First Byte Enable和Last DW Enables需要实现为1111b
Flit模式下的TLP Header
Flit Mode下所有TLP Header都具有如下内容
根据OHC[4:0]的值,在第一个DW后面可以跟0到7个OHC
Non-Flit和Flit模式一些显著的不同:
- Non-Flit模式下的End-to-End prefixes在FLIT模式下合并到Header中的OHC去了,所有FLIT模式下不存在End-to-End prefixes
- Flit模式下,Steering Tags不会覆盖Byte Enables. PH, Steering Tags 和 AMA/AV 字段跟OHC关联。
一些规则:
- 当没有有内容的TLP需要传输时,必须发送NOP TLPs,接收机必须丢掉NOP TLPs,并且不能对接收方产生任何影响,对于NOP TLPs而言,header中除了Type字段有意义外,其它所有字段都是保留的
- 对于所有的Reserved项目,TLP路由必须按照Description字段的指示进行处理,并且无论Header Base格式是否是保留的,用于路由的Header Base字段都是在相同的位置。对于标记为”Local … Terminate t receiver”的项必须在接受端口丢掉
- Endpoint Upstream Port和Root Ports如果收到的TLP中,Type[7:0]的编码为FC Type PR或 NRP,则必须当成保留的编码来处理,当成UR,如果收到的Cpl,则处理为UC
- 使用FC Type PR的UIO请求被称为UIO PR-FC TLPs, 使用FC Type NPR的UIO请求被称为UIO NPR-FC TLPs
- UIO只有在Flit Mode下有定义,在NFP模式下,不翻译UIO TLP是允许的
Type字段
- Type[7:0]总共256种编码,详情可参考协议。此字段是用来决定TLP的类型,FC类型,是否具有Data Payload, Header Base大小以及转换规则。
- 即使接收机不支持支持Type[7:0]的所有编码,但是也必须能够解码出来。
- 如果Type[7:0]表明该TLP跟Flow Control(FC)相关,接收机必须要能够处理。
- 对于FC Type为空的TLPs,接收机不需要缓冲该TLP,并且必须静默丢掉该TLP
- 对于其它FC类型,switch Port必须缓存和路由该TLP,包括保留的一些内容;Endpoint Upstream Ports和Root Ports需要缓存下来,包括Header的记录,直到最大的Header Base Size加上所有的OHC内容,但是在Flow Control完成后,允许丢弃port不支持的Header Base和OHC内容,并且不将这些信息包括在报头日志中。
OHC字段
OHC[4:0]用于表明OHC(Orthogonal Header Content)是否存在,编码如下:
| OHC[4:0] | 含义 |
|---|---|
| 0 0000b | 不存在OHC |
| x xxx1b | 存在OHC-A |
| x xx1xb | 存在OHC-B |
| x x1xxb | 存在OHC-C |
| 0 0xxxb | 不存在OHC-E |
| 0 1xxxb | 存在OHC-E1 |
| 1 0xxxb | 存在OHC-E2 |
| 1 1xxxb | 存在OHC-E4 |
当OHC存在时,OHC必须跟在Header Base的后面(TLP中Data Payload前),并且允许有多个OHC的组合。但是,当多个不同的OHC时,跟在Header Base后时,必须采用A-B-C-E的顺序,即OHC-A必须在OHC-B前面。
比如存在OHC-A5时,OHC-A5具有如下的格式
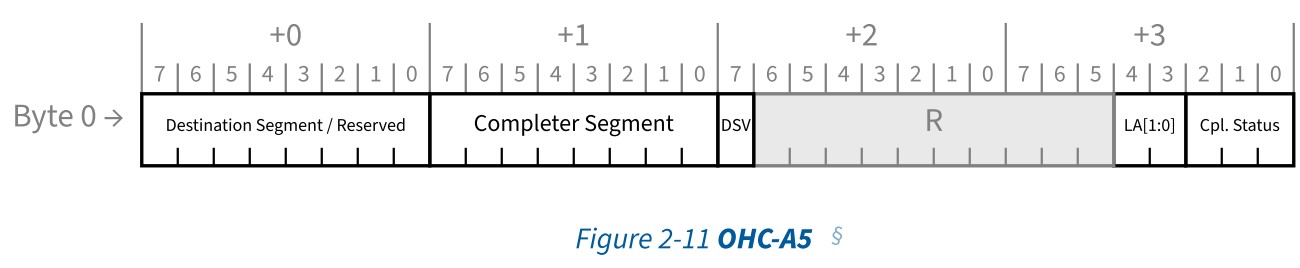
OHC-A5在Header Base的后面,具有下列的形式
OHC其它部分图片较多,见另外一篇文章。
TS字段
TS[2:0]字段用于表明Trailer的大小。
| 编码 | Trailer 大小 |
|---|---|
| 000b | 没有 Trailer |
| 001b | 1DW Trailer,包含ECRC |
| 010b | 1DW Trailer,内容保留 |
| 011b | 2DW Trailer,内容保留 |
| 100b | 2DW Trailer,内容保留 |
| 101b | 3DW Trailer,只有OHC-C存在时才包含IDE MAC,表明是一个IDE TLP,其它情况内容保留 |
| 110b | 4DW Trailer,只有OHC-C存在时才包含IDE MAC,表示时一个IDE TLP,其它情况保留 |
| 111b | 5DW Trailer,内容保留 |
其它字段
TC,Attr和Length字段跟non flit模式一样。LN(Byte 1 bit 1)在Flit模式下不支持。
TLP Data Payload 规则
Length 规则
- TLP 的长度必须是双字(DW : Double Word, 32 bit)的整数倍
- Length[9:0] 对所有消息类型(Message)的 TLP 来说是保留的, 除非是显式引用数据长度的消息类型(如MsgD)
- 对于包含数据的 TLP, 在 TLP Header 中的 length 字段必须与实际 TLP 的数据长度相匹配
- 在 NFM 中,接收机必须检查该项规则,如果违反该条规则,该 TLP 是一个 Malformed TLP. 这是一个与接收端口相关的报告错误。
- TLP Header 的 Length 字段只应用数据, TLP digest 不包含在 Length 字段所规定的长度之内
MPS规则
- MPS : Max Payload Size
Tx MPS规则
- 发送带有数据载荷的TLP时,其数据载荷长度是由TLP’s Length字段决定,TLP数据载荷的长度不允许超过该function的MPS设置
- 如果Device Capabilities寄存器的Mixed_MPS_Supported是1,则可以针对不同的目标设置不同的MPS值,该机制是基于具体设计实现。
- 如果Device Capabilities寄存器的Mixed_MPS_Supported是1,则该function必须必须能处理Requeste和Completion TLPs.
- 如果Function’s的Mixed_MPS_Supported比特是0或者目标是host memory,合适的MPS 值必须由Function 计算出来的Tx_MPS_Limit值. Tx_MPS_Limit规定如下:
- Tx_MPS_Limit的值不能超过Device Capabilities寄存器中Max_Payload_Size Supported的值
- 如果是单功能设备,Tx_MPS_Limit必须是Max_Payload_Size域段的值,也就是MPS设置的值
- 如果是ARI设备,Function 0的Tx_MPS_Limit必须是MPS设置的值。多功能设备的其它Function的MPS必须忽略
- 如果是不支持 ARI 的多功能设备且所有功能都具有相同的MPS设置,则某个功能的 Tx_MPS_Limit 必须是通用的MPS设置
- 如果是不支持 ARI 的多功能设备且不是所有功能的MPS都相同,则某个功能的Tx_MPS_Limit值是基于具体实现。
- 鼓励发射机使用某个function产生事务的MPS设置,或者使用使用所有function中最小的MPS设置
- 软件不应该给不同的功能配置不同的MPS值,除非软件意识到Tx_MPS_Limit 是基于具体实现
- Max_Payload_Size 只应用在带有数组载荷的 TLP, Memory Read 请求不是严格受到 Max_Payload_Size 值的约束,Memory Read 请求是由 Length 控制
- 发射机的 Device Control 寄存器的 Max_Payload_Size (最大数据载荷)字段必须要为双字(DW)的整数倍, 发射机如果发送带有数据载荷的 TLP, 其 TLP 中的 Length 字段不允许超过 Max_Payload_Size 的值。
Rx MPS规则
- 数据载荷的大小是由收到 TLP 的 Length 字段决定的,该字段不能超过计算的 Rx_MPS_Limit。接受必须检查此项规则,如果接收机认为 TLP 违反了该项规则,该 TLP 必须处理为 Malformed TLP, 并且需要上报错误,错误需要跟接受端口绑定
- 在 Flit 模式下,接收机必须处理长度字段的全部内容,以便确定每个 TLP 的总大小,并确定哪个符号是下一个 TLP 的起始位置。在接收机的功能中,如果 Rx_MPS_Fixed 是 1,Rx_MPS_Limit必须是 Max_Payload_Size_Supported 域
- 在接收机的功能中,如果 Rx_MPS_Fixed是 0,Rx_MPS_Limit 由下决定
- 如果是单功能设备,Rx_MPS_Limit必须是它自己的 MPS 设置。
- 如果是支持 ARI 的设备,Rx_MPS_Limit必须是“功能0”的 MPS 设置值。其它功能的 MPS 设置必须被忽略。
- 对于 Upstream Port 来说, 如果是一个不支持ARI多功能设备(Multi-Function Device,MFD), 别切 MPS 设置在所有功能中都是一样的,则 Rx_MPS_Limit必须是公用的 MPS 设置
- 对于 Upstream Port 来说, 如果是一个不支持 ARI 的多功能设备且 MPS 在不同的功能上设置不同,则某个功能的 Rx_MPS_Limit 值是基于具体实现
- 鼓励接收机实现使用事务所针对的 Function 的Max_Payload_Size设置,或者使用所有 Function 中最大的Max_Payload_Size设置。
- 软件不应该在不同的功能中设置不同的 MPS 值,除非软件意识到Rx_MPS_Limit 是基于具体实现
数据排列规则
- 当与字节地址相关的数据负载被包含在 TLP 中,但该 TLP 不是原子操作请求或原子操作完成块时,位于头部之后的第一个数据字节对应于离零最近的字节地址,而后续的字节则按照字节地址递增的顺序排列。
- 示例:对于向 100h 位置进行的 16 字节写入操作,位于头部之后的第一个字节将是要写入到 100h 位置的字节,第二个字节将被写入到 101h 位置,以此类推,最后一个字节将被写入到 10Fh 位置。
- 在“原子操作请求”和“原子操作完成”中,数据有效负载的格式必须确保:在传输块头信息之后的第一个数据字节是第一个数据值的最低有效位,而后续的数据字节的数值则按递增的显著性顺序排列。
- 在比较交换(CAS)请求中,第二个数据值紧随第一个数据值之后,并且必须采用相同的格式。
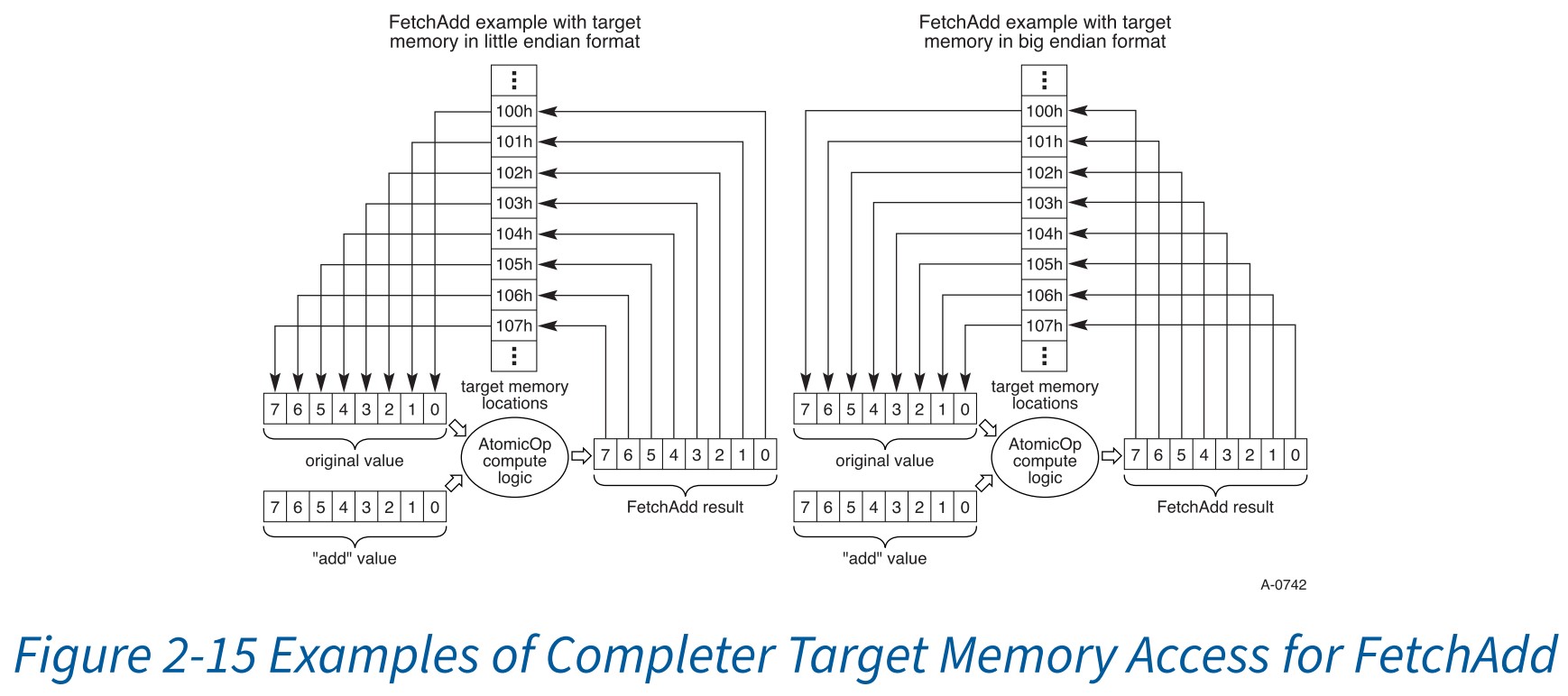
- 原子操作完成器 (Completers)用于在目标位置读取和写入数据所采用的字节序格式是具体的实现方式,可以由完成器自行决定,只要其确定这种格式对于目标内存而言是合适的即可(例如,小端序、大端序等)。原子操作完成器的字节序格式能力报告和控制不在本规范的范围之内。
- 小端序示例:对于一个针对位置 100h 的 64 位(8 字节)交换请求,目标内存采用小端序格式,那么在头部之后的第一个字节会被写入位置 100h,第二个字节会被写入位置 101h,依此类推,最后一个字节会被写入位置 107h。请注意,在执行写入操作之前,完成者会先读取目标内存位置,以便在完成结果中返回原始值。完成结果中字节地址与数据的对应关系与请求中的对应关系相同。**
- 大端序示例:对于一个针对位置 100h 的 64 位(8 字节)交换请求,目标内存采用大端序格式,那么在头部之后的第一个字节将被写入位置 107h,第二个字节写入位置 106h,依此类推,最后一个字节写入位置 100h。请注意,在执行写入操作之前,完成者会先读取目标内存位置,以便在完成结果中返回原始值。完成结果中字节地址与数据的对应关系与请求中的对应关系相同。
TLP Digest
TLP Digest 规则
只适用于Non Flit模式
对于任何 TLP 而言, TD 字段为 1 表明 TLP Digest 存在, 也包括TLP 末尾端到端的 CRC (end-to-end CRC, ECRC)。如果收到的 TLP 中, TD 字段与观察到的TLP长度不一致(如果TD存在), 则该 TLP 是一个 Malformed TLP。且需要上报错误,该错误需要跟 port 绑定。比如 TLP 中的 TD 字段为 1, 但是 TLP 中并没有 ECRC
如果中间一级或者最终的 PCIe 接收机不支持 ECRC 检查, 接收机必须忽略 TLP Digest。如果接收机支持 TLP 的 ECRC 检查, 接受机会把 TLP Digest 的值当作 ECRC 的值
感谢您的支持,请扫码打赏

